-

Invited Speakers
Intrinsically motivated AI agent modeling in MAS
-

Paper Presenation
Cognitive Modeling in Cooperative MAS
-

Topic Discussion
Human-Multi-Aegnt Interaction
About
This workshop focuses on the role of decision-making and learning in human-multi-agent cooperation, viewed through the lens of cognitive modeling. AI technologies, particularly in human-robot interaction, are increasingly focused on cognitive modeling, encompassing everything from visual processing to symbolic reasoning and action recognition. These capabilities support human-agent cooperation in complex tasks.
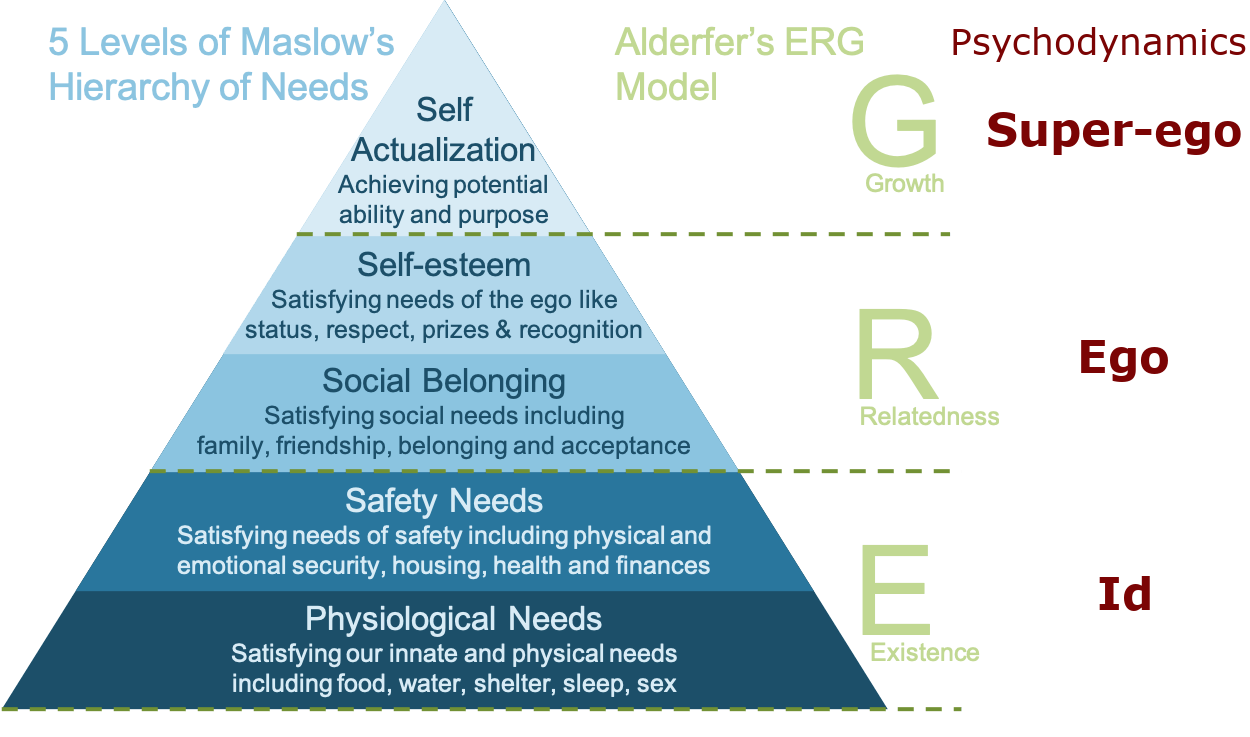 Natural agents, like humans, often make decisions based on a blend of biological, social, and cognitive motivations, as elucidated by combined motivations' model like Maslow’s Hierarchy of Needs and
Alderfer’s Existence-Relatedness-Growth (ERG) theory. On the other hand, the AI agent can be regarded as a self-organizing system that also presents various needs and motivations
in its evolution through decision-making and learning to adapt to different scenarios and satisfy their needs. Combined with AI agent capacity to aid decision-making, it opens up new horizons in human-multi-agent collaboration.
This potential is crucially essential in the context of interactions between human agents and intelligent agents, when considering to establish stable and reliable relationships in their cooperation,
particularly in adversarial and rescue mission environments.
Natural agents, like humans, often make decisions based on a blend of biological, social, and cognitive motivations, as elucidated by combined motivations' model like Maslow’s Hierarchy of Needs and
Alderfer’s Existence-Relatedness-Growth (ERG) theory. On the other hand, the AI agent can be regarded as a self-organizing system that also presents various needs and motivations
in its evolution through decision-making and learning to adapt to different scenarios and satisfy their needs. Combined with AI agent capacity to aid decision-making, it opens up new horizons in human-multi-agent collaboration.
This potential is crucially essential in the context of interactions between human agents and intelligent agents, when considering to establish stable and reliable relationships in their cooperation,
particularly in adversarial and rescue mission environments.
This workshop will bring together researchers from multi-agent systems (MAS) and human-robot interaction (HRI) and aims to advance the field by exploring how cognitive science, mathematical modeling, statistical analysis, software simulations, and hardware demonstrations can help answer critical questions about decision-making and learning in these cooperative environments. The goal is to understand better how cognitive modeling can enhance cooperation between humans and AI agents, especially in complex, high-stakes scenarios.
Topics
We solicit contributions from topics including but not limited to:
- Human-multi-agent cognitive modeling
- Human-multi-agent trust networks
- Trustworthy AI agents in Human-robot interaction
- Trust based Human-MAS decision-making and learning
- Consensus in Human-MAS collaboration
- Intrinsically motivated AI agent modeling in Human-MAS
- Innate-values-driven reinforcement learning
- Multi-Objective MAS decision-making and learning
- Adaptive learning with social rewards
- Cognitive models in swarm intelligence and robotics
- Game-theoretic approaches in MAS decision-making
- Cognitive model application in intelligent social systems

AI is TERMINATOR or "Data" (Star Trek)?
Videos
Workshop Video: Part 1 (9:00 am -- 11:10 am) -- Invited Speaker Session 1 and Oral Presentation
Workshop Video: Part 2 (11:25 am -- 12:25 pm) -- Invited Speaker Session 2
Workshop Video: Part 3 (1:20 pm -- 3:30 pm) -- Invited Speaker Session 3 and Poster Presentation 1 & 2
Workshop Video: Part 4 (3:45 pm -- 6:00 pm) -- Invited Session 4 and Expert Panel Discussion
Invited Speakers








Workshop Schedule
| All times in EST (GMT-5), Mar. 03, 2025 (Pennsylvania Convention Center, Room 120B) | |
| 9:00a | Welcome Remarks |
| 9:10a | Invited Session 1 |
| 9:10a-9:40a |
Peter Stone (University of Texas at Austin) - Topic: Advances in Ad Hoc Teamwork: Multiagent Collaboration without Pre-Coordination
Abstract: As autonomous agents proliferate in the real world, both in software and robotic settings, they will increasingly need to band together for cooperative activities with previously unfamiliar teammates. In such "ad hoc" team settings, team strategies cannot be developed a priori. Rather, an agent must learn to cooperate with many types of teammates: it must collaborate without pre-coordination. This talk will summarize research along two recent directions of ad hoc teamwork. First, it will consider how to generate diverse teammates for the purpose of training a robust ad hoc teamwork capability. Second, it will introduce a new generalization of ad hoc teamwork, called N-agent ad hoc teamwork, in which a collection of autonomous agents must interact and cooperate as a subteam with dynamically varying numbers and types of teammates. |
| 9:40a-10:10a |
Katia Sycara (Carnegie Mellon University) - Topic: Modeling Trust in Human-Swarm Collaboration
Abstract: Robotic swarms consist of simple, typically homogeneous robots that interact with other robots and the environment. Swarm robots are coordinated via simple control laws to generate emergent behaviors. Owing to their scalability and natural robustness to individual robot failures, swarms are attractive for large-scale applications in unstructured and dynamic environments. Human presence is important in swarm applications since humans can recognize and mitigate shortcomings of the swarm, such as limited sensing and communication. Also, humans can provide new goals to the swarm as the environment and mission requirements dictate. In such interactions, correct trust calibration to the swarm is crucial for task performance. By correctly trusting the swarm, the operator can leave the swarm undisturbed to perform the task at hand. On the other hand, if swarm performance degrades, the operator can provide appropriate corrective interventions. In this talk I will discuss the challenges in formulating human-swarm interaction models and provide examples for different scenarios. Additionally, I will present empirical results from human experiments and discuss open problems and research directions. |
| 10:10a |
Contributed Papers - Oral Presentations
10:10a-10:22a --- Innate-Values-driven Reinforcement Learning |
| 11:10a-11:25a | Coffee Break |
| 11:25a | Invited Session 2 |
| 11:25a-11:55a |
Benjamin Kuipers (University of Michigan) - Topic: Trust is a Utility
Abstract: Trust, or more precisely, a reputation for trustworthiness, is a capital asset for an individual decision-maker. One benefit to an individual of trust from others is increased opportunity to participate in cooperative, positive-sum, activities with those others. By explicitly considering trust, each individual decision takes place in the context of a society, with many and varied decision-makers and many and varied decisions to make. Actions that deplete that asset decrease the individual’s ability to cooperate, their ability to respond to threats and opportunities, and perhaps even their survival. Since trust is so important to the decision-maker, it must be included in the utility measure. The value of an action selected by a utility-maximization algorithm depends critically on how the utility measure is defined. In the classic Prisoner’s Dilemma, the utility-maximization algorithm selects a shockingly bad action. The proper conclusion is that the algorithm was applied to an incorrect model of the decision situation, in this case by omitting trust from the utility measure. A second benefit of trust to a decision-maker is to simplify the model of the world, making planning more tractable by reducing the need for contingency planning. One trusts that cooperative partners will act in certain reliable and benevolent ways, and that certain unlikely results of actions will not occur. Of course, assumptions like these are not always true. People do sometimes break their promises, run red lights, or fail to repay their debts. Trust has substantial value, but is also vulnerable to exploitation. How should intelligent agents, human and artificial, behave and reason to maximize gains from trust-based cooperation and minimize losses from trust failures? In order to survive and thrive through cooperation, our human society has evolved a variety of methods for estimating the trustworthiness of potential partners, and for anticipating and responding to trust failures. Our goal is to identify, formalize, and implement these methods to encourage trust and cooperation in a society including artificially intelligent agents as well as human beings. |
| 11:55a-12:25p |
Panagiotis Tsiotras (Georgia Institute of Technology) - Topic: Training Multi-Agent Reinforcement Learning Games with Mean Field Interactions
Abstract: State-of-the-art multi-agent reinforcement learning (MARL) algorithms such as MADDPG and MAAC fail to scale in situations where the number of agents becomes large. Mean-field theory has shown encouraging results in modeling large-scale agent behavior in large teams through a continuum approximation of the agent population and its interaction with the environment. Although MF approximations have been used extensively in MF control problems, the fully adversarial case has received less attention. In this talk, we will investigate the behaviors of two large population teams competing in a discrete environment, The team-level interactions are modeled as a zero-sum game, while the dynamics within each team are formulated as a collaborative mean-field team problem. Following the mean-field literature, we first approximate the large-population team game with its infinite-population limit. By introducing two fictitious coordinators we transform the infinite-population game into an equivalent zero-sum coordinator game. We study the optimal strategies for each team for the infinite population limit via a novel reachability analysis, and we show that the obtained team strategies are decentralized and are ε-optimal for the original finite-population game. This allows the training of competing teams with hundreds or thousands of agents. We will demonstrate the application of this theoretical result to agent training in large-population multi-agent reinforcement learning (MARL) problems. |
| 12:25p-1:20p | Lunch Break |
| 1:20p |
Contributed Papers - Poster Session I
1:20p-1:25p --- Hierarchical and Heterogeneous MARL for Coordinated Multi-Robot Box-Pushing Environment |
| 2:00p | Invited Session 3 |
| 2:00p-2:30p |
Sven Koenig (University of California, Irvine) - Topic: Multi-Robot Systems: Ant Robots and Auction Robots
Abstract: Ant robots have the advantage that they are easy to program and cheap to build. We study ant robots for the one-time or repeated coverage of terrain. They cannot use conventional planning methods due to their limited sensing and computational capabilities. To overcome these limitations, we study navigation methods that leave markings in the terrain, similar to what real ants do. These markings are shared among all ant robots and allow them to cover terrain even if they do not have any kind of memory, cannot maintain maps of the terrain, nor plan complete paths. Our navigation methods do not require the ant robots to be localized. They can be used by single ant robots and groups of ant robots and are robust even if the ant robots are moved without realizing this (say, by people running into them), some ant robots fail, and some markings get destroyed. Auction robots have to repeatedly reassign tasks among themselves, for example, as they learn more about the terrain, as robots fail, or as additional tasks get introduced. We study auction-based robot coordination systems that assign locations to robots (that then need to visit these locations) and are based on sequential single-item auctions. They can - perhaps surprisingly - provide constant-factor quality guarantees in some cases even though they run in polynomial time and, more generally, combine the advantageous properties of parallel and combinatorial auctions. For a given number of additional locations to be assigned during each round, the communication and winner determination times do not depend on the number of locations, which helps them to scale up to many locations for small bundle sizes. |
| 2:30p-3:00p |
Maria Gini (University of Minnesota) - Topic: Can I trust my teammates? Are they friends or foes?
Abstract: Autonomy in a multi-robot system refers to the ability to make decisions and perform tasks independently. To be successful, robots must be equipped with adequate sensors to gather data and actuators, so they can make decisions accordingly. But this is not enough. There is the potential for some team members not to be cooperative. They could simply be lazy, or slow at doing their work, perhaps due to battery problems or sensor failures, but they could also intentionally disrupt the work of the team. How can those undesirable behaviors be detected? Recognition of potential issues and adaptation are necessary, especially for critical and time-sensitive tasks. We propose to measure trust using a model of trust that has been proposed in the agents community and present preliminary results. |
| 3:00p |
Contributed Papers - Poster Session II
3:00p-3:05p --- Training Adaptive Foraging Behavior for Robot Swarms Using Distributed Neuroevolution of Augmented Topologies |
| 3:30p-3:45p | Coffee Break |
| 3:45p | Invited Session 4 |
| 3:45p-4:15p |
Matthew E. Taylor (University of Alberta) - Topic: Where do rewards come from? Examining rewards via a multi-agent lens.
Abstract: Reinforcement learning (RL) has had lots of great successes, but it presumes that an environmental reward exists and is correct. This talk will discuss two extensions to the typical RL framework. First, consider the setting where an environmental reward exists, but may not always be observable to the agent. I will discuss a series of papers that introduce the Monitored MDP framework, where agents explicitly reasoning about how they can observe the reward, whether it comes from an environment, another agent, or a human. Second, consider what happens if there is no ground truth MDP to hand an agent and a researcher must first define it. A critical factor is how a person defines a reward function, and if they change the reward function over time. I will what can go wrong if there misalignment between the agent and the human designer and recent work on best practices for reward design. |
| 4:15p-4:45p |
Kevin Leyton-Brown (University of British Columbia) - Topic: Human-Like Strategic Reasoning via ML
Abstract: This talk will survey two recent projects at the intersection of modeling human-like reasoning in economic settings and modern machine learning. First, models of human behavior in game-theoretic settings often distinguish between strategic behavior, in which a player both reasons about how others will act and best responds to these beliefs, and "level-0" non-strategic behavior, in which they do not respond to explicit beliefs about others. The talk will survey recent work that shows that the existing state-of-the-art method for predicting human play in games has an invalid level-0 specification (i.e., it is capable of strategic reasoning); that fixes this via a novel neural network architecture; and that shows experimentally that the new architecture is equally accurate for prediction while being more economically understandable. Second, there is growing interest in using LLMs as economic agents, raising the question of when they should be trusted. The talk will describe an approach for comprehensively benchmarking an LLM's ability to perform both strategic (e.g., game-theoretic) and non-strategic (e.g., microeconomic) decision-making, powered by a novel LLM-assisted data generation protocol. We demonstrate the usefulness of our benchmark via a case study on 27 LLMs, ranging from small open-source models to the current state of the art, showing cases where LLMs achieve reliable performance and where they still struggle, and highlighting some qualitative patterns in the errors they make. |
| 4:45p-5:35p | Expert Panel Discussion |
| 5:35p-5:40p | Concluding Remarks |
Contributions
Oral Presentation
| [#1] | Innate-Values-driven Reinforcement Learning, Qin Yang [Link to Paper] [Link to Poster] |
| [#2] | What are you saying? Towards explaining communication in MARL, Cristian Morasso, Daniele Meli and Alessandro Farinelli [Link to Paper] [Link to Poster] |
| [#6] | Incentive Design in Hedonic Games with Permission Structures, Yuta Akahoshi, Yao Zhang, Kei Kimura, Taiki Todo and Makoto Yokoo [Link to Paper] [Link to Poster] |
| [#15] | Detecting Adversarial Interference in Cooperative Tasks Through Multi-dimensional Bayesian Trust Metric, Angel Sylvester and Maria Gini [Link to Paper] [Link to Poster] |
| [#16] | Towards Multi-Agent Spatio-Temporal Area Restoration, Amel Nestor Docena and Alberto Quattrini Li [Link to Paper] [Link to Poster] |
Posters
| [#17] | Hierarchical and Heterogeneous MARL for Coordinated Multi-Robot Box-Pushing Environment, Ebasa Temesgen, Sarah Boelter and Maria Gini [Link to Paper] [Link to Poster] |
| [#8] | Digital Twin Synchronization for Real-Time Process Control Using Sim-RL in Smart Additive Manufacturing, Matsive Ali, Sandesh Giri, Sen Liu and Qin Yang [Link to Paper] [Link to Poster] |
| [#10] | On the Decision-Making Abilities in Role-Playing using Large Language Models, Chenglei Shen, Guofu Xie, Xiao Zhang and Jun Xu [Link to Paper] [Link to Poster] |
| [#11] | Enabling Rapid Shared Human-AI Mental Model Alignment via the After-Action Review, Edward Gu, Hosea Siu, Melanie Platt, Isabelle Hurley, Jaime Peña and Rohan Paleja [Link to Paper] [Link to Poster] |
| [#13] | Recovering Reward Functions from Distributed Expert Demonstrations with Maximum-likelihood, Guangyu Jiang, Mahdi Imani, Nathaniel Bastian and Tian Lan [Link to Paper] [Link to Poster] |
| [#18] | Training Adaptive Foraging Behavior for Robot Swarms Using Distributed Neuroevolution of Augmented Topologies, Tameem Uz Zaman, Pigar Biteng, Eric Rodriguez and Qi Lu [Link to Paper] [Link to Poster] |
| [#4] | “I apologize for my actions”: Emergent Properties and Technical Challenges of Generative Agents, N'Yoma Diamond and Soumya Banerjee [Link to Paper] [Link to Poster] |
| [#5] | MASR: Multi-Agent System with Reflection for the Abstraction and Reasoning Corpus, Kiril Bikov, Mikel Bober-Irizar and Soumya Banerjee [Link to Paper] [Link to Poster] |
| [#9] | Comparative Analysis of Multi-Agent Reinforcement Learning Policies for Crop Planning Decision Support, Anubha Mahajan, Shreya Hegde, Ethan Shay, Daniel Wu and Aviva Prins [Link to Paper] [Link to Poster] |
Organizing Committee

Qin Yang
Assistant Professor,Intelligent Social Systems and Swarm Robotics Lab (IS3R),
Bradley University



Christopher Amato
Associate Professor,Lab for Learning and Planning in Robotics,
Northeastern University
Submission
Submissions can contain relevant work in all possible stages, including those recently published work, is under submission elsewhere, was only recently finished, or is still ongoing. Authors of papers published or under submission elsewhere are encouraged to submit these papers or short versions (including abstracts) to the workshop, educating other researchers about their work, as long as resubmissions are clearly labeled to avoid copyright violations.
We welcome contributions of both short (2-4 pages) and long papers (6-8 pages) related to our stated vision in the AAAI 2025 proceedings format. Position papers and surveys are also welcome. The contributions will be non-archival but will be hosted on our workshop website. All contributions will be peer reviewed (single-blind).
Workshop paper submission deadline: 6 December 2024, 11:59 pm Pacific Time.
Notification to authors: 25 December 2024.
Camera-ready submission deadline: 20 January 2025.
Acceptance papers will be made publicly available on the workshop website. These non-archival papers and their corresponding posters will also remain available on this website after the workshop. The authors will retain copyright of their papers.
Please contact is3rlab@gmail.com with any questions.
Past Events
The first workshop: "Cooperative Multi-Agent Systems Decision-Making and Learning: From Individual Needs to Swarm Intelligence" in AAAI 2024 #W13.
Copyright 2024 IS3R Lab | All Rights Reserved -- by is3rlab.org